Data virtualization allows partial retrieval of data from a data source on an "as needed" basis. Xceed DataGrid for Silverlight takes that basic concept and pushes it even further by constantly preserving UI responsiveness through asynchronous data retrieval and automatic pre-fetching of data. To make things even better, if your data source is using WCF Data or RIA Services, it all happens behind the scenes! Just pass the data-service or entity query to the datagrid control and everything else happens auto-magically.
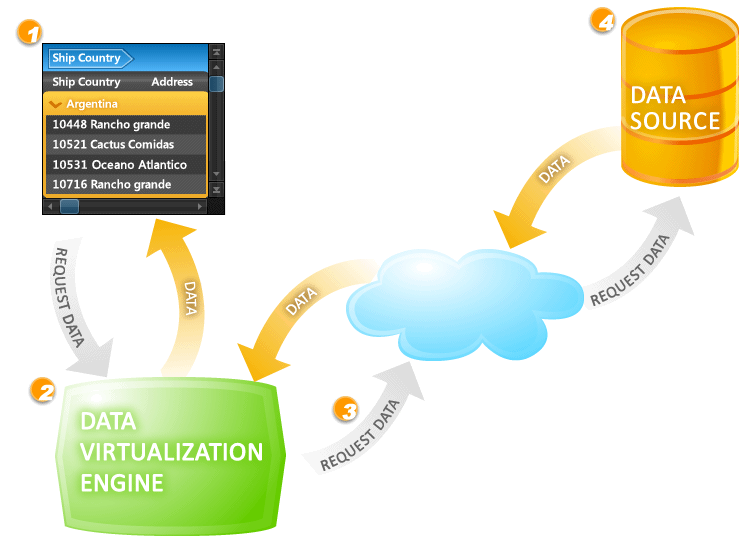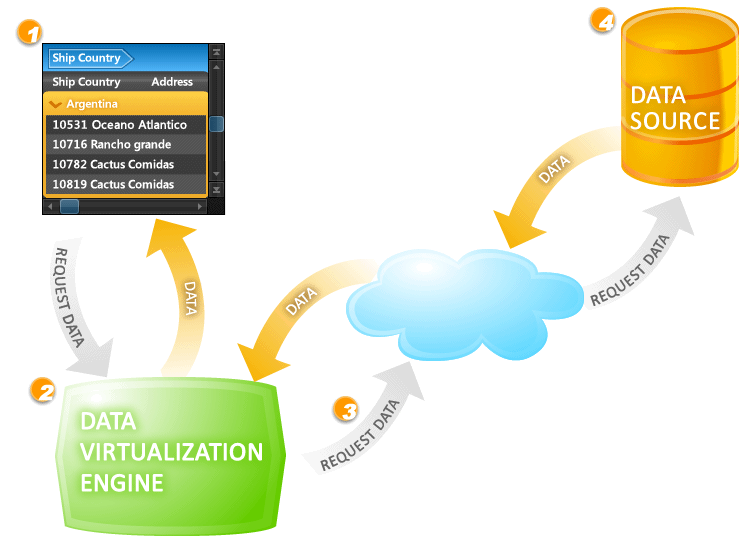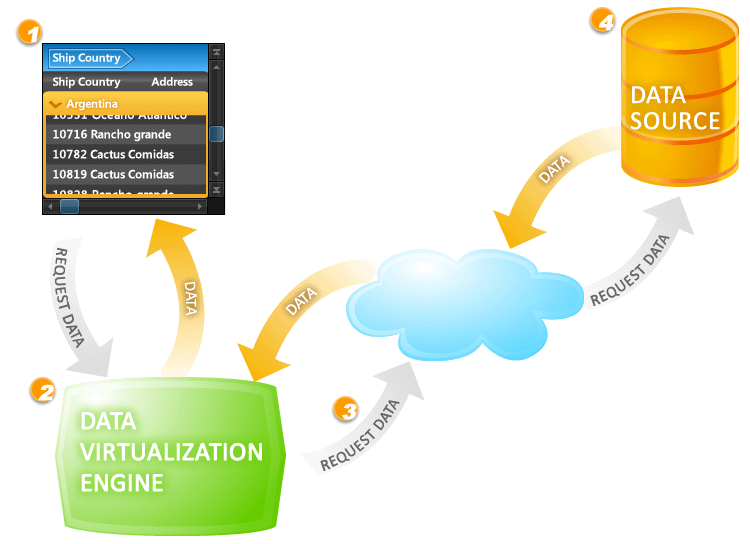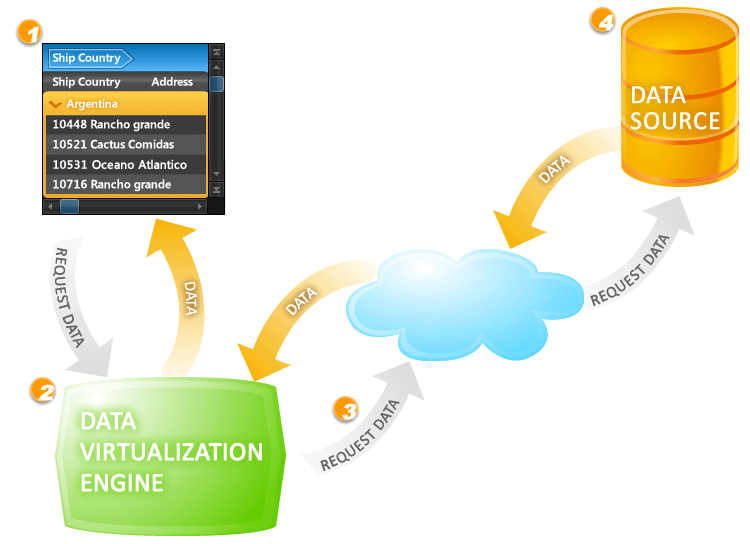
The whole idea behind the data virtualization capabilities provided by Xceed DataGrid for Silverlight is to leave the application responsive at all times, even when data is being retrieved from a remote data source. So, to give you a better idea of what is going on behind the scenes let's take a look at the diagram below.
When scrolling through the grid (1), items that are currently not loaded are requested by the grid from the data-virtualization engine (2). If the engine has a cache of data available, it will be returned immediately and the grid will simply update to display the data. If data outside of the cache is requested, the request will be passed from the data-virtualization engine (3) to the remote data source where it will be processed (4) and the newly fetched data returned to the engine where it will then be passed to the grid. In both situations, the grid will always remain completely responsive.
In addition, sorting, grouping, and non-predicate filtering are tasks that are performed on the server, further reducing the processing time and transfers needed on the client machine.
The Data-Virtualization Engine
The data-virtualization engine behind Xceed DataGrid for Silverlight is the invisible maestro that orchestrates all the behind-the-scenes data management. Although it is the cornerstone on which Xceed DataGrid for Silverlight was built, in most cases, you will never have to deal with it and will only know that it is working because everything is working so well. To get a little bit more technical, the data-virtualization engine is basically a layer of enumerators that each manipulate and process the data items that are displayed in the grid, all the while making sure that "extra" items are available, just in case.
Take a look at the image below and consider a simple operation, such as a line down (i.e., "Get(1)"):
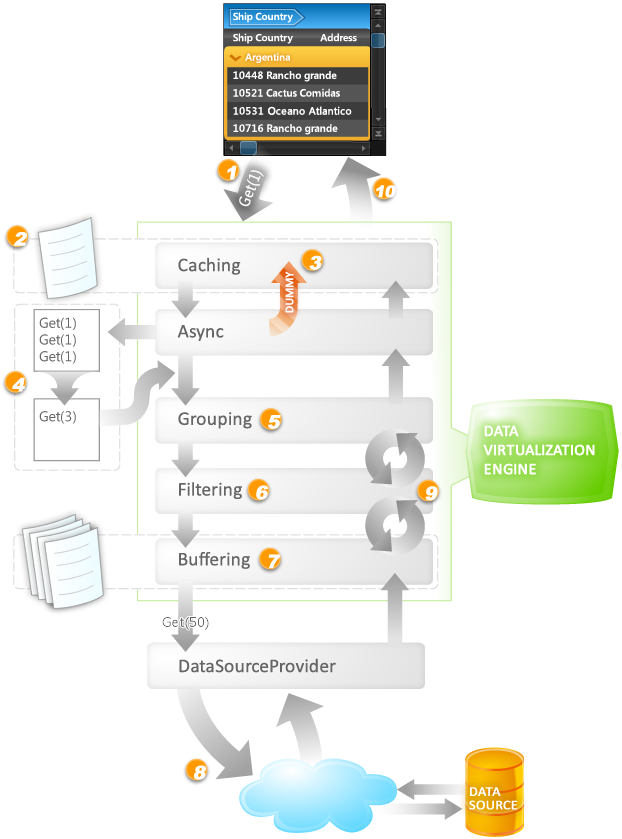
When the grid requires new items (1), the request is processed by the data-virtualization engine, which begins its initial pass by querying the caching enumerator to see if it has the data items that are needed (2). If the caching enumerator has the items, they are immediately returned and displayed in the grid (10). If the caching enumerator does not contain the required items, the request is sent to the async enumerator, which will create and immediately return "dummy" items (3) so that the grid remains responsive even though there is a pending request to retrieve new items. The request will then be queued along with any additional pending requests. The async enumerator is also responsible for optimizing the query that is sent to the subsequent enumerators. For example, if three line down operations are queued, the async enumerator will condense these pending operations into a single "Get(3)" query, thereby only sending one request to the next enumerator rather than three (4). Obviously, if there is only one pending request within a reasonable lapse of time, it will be sent as-is to the next enumerator.
Once the async enumerator has optimized the pending queries, the resulting query is sent to the grouping enumerator, which takes care of appending any grouping criteria (i.e., "OrderBy") to the query that is being sent to the data source (5). Once the grouping enumerator has added its requirements, the query is passed to the filtering enumerator, which may also append its filtering criteria if it is using a filter expression (6). If a predicate is being used to filter the items, the information will not be appended to the query and the unmodified query will be sent to the buffering enumerator, which is next in line. The buffering enumerator, which typically contains multiple pages of data that has been fetched from the data source, is the last layer before the query is handed over to the data-source provider. Now, the buffering enumerator has an additional role, which is it make sure that it makes a worthwhile roundtrip to the server. If it realizes that the trip is "not worth it," as in this example of only retrieving three items, it will decide to get more items and keep them in its buffer (7). Once the query exits the data-virtualization engine, the data-source provider takes over and queries the data source using the transformed query (8).
All this time, the grid has remained fully responsive.
Once the data-source provider receives the items from the data source, they are handed to the buffering enumerator, which passes the items that were requested to the filtering enumerator and buffers the rest for later use. At this point, if a predicate is being used to filter the items, it is possible that the filtering enumerator rejects the items that are received and requests more from the buffering enumerator, which luckily grabbed more than was requested. If only a filter expression was used, then the items are passed directly from the filtering to the grouping enumerator. Like the filtering enumerator, it is possible that the grouping enumerator rejects the items. For example, if the items belong to a collapsed group, they will be rejected and new items will be requested (9). Of course, the grouping enumerator will modify the request to make sure that further requests will "jump" over collapsed groups.
After the items have successfully passed the lower enumerators, they are finally transferred to the async enumerator that will replace the dummy items with the actual items, which will then be displayed in the grid (10).
In addition to the enumeration layers, Xceed DataGrid for Silverlight also actively pre-fetches new items and rebalances the caching and buffering enumerators while the data-virtualization engine is idle. What this means is that when there are no pending requests in the async enumerator, the engine will actively retrieve new items and make sure that the currently displayed items are moved to the middle of the buffers. In other words, if the currently displayed items are located at the end of the buffer, they will be moved to the middle, the extra items at the top will be cleared, and new items will be fetched to complete the buffer.
 |
By default, a grid will take all the room that it requires; therefore, if it is not given a size constraint, such as when it is placed in a StackPanel, and a large amount of data items are present, UI virtualization will be lost—resulting in a significant loss in performance. To preserve UI virtualization when a grid is in a StackPanel, the MaxWidth and MaxHeight properties (or Width and Height) must be used to constrain the grid. As an alternative, a DockPanel or Grid can be used as both impose size constraints on their child elements. |